
fsck not repairing corruption on boot
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| e2fsprogs (Ubuntu) |
Invalid
|
Undecided
|
Unassigned | ||
| sysvinit (Ubuntu) |
Fix Released
|
High
|
Martin Pitt | ||
Bug Description
Binary package hint: e2fsprogs
I suffered some disk corruption see Bug #209346
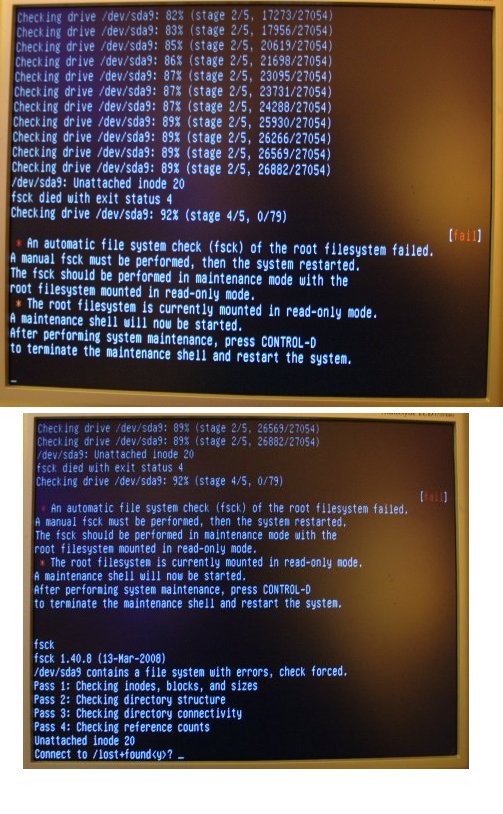
On rebooting fsck stopped at 15% and the computer rebooted. this loop of fscking and rebooting continued for a while.
i did the nosplash thing and got the following
* Checking root file system...
1254
fsck 1.40.8 (13-Mar-2008)
/dev/sda9 contains a file system with error, check forced.
Checking drive /dev/sda9: 0% (stage 1/5, 1/79)
Checking drive /dev/sda9: 1% (stage 1/5, 1/79)
...
Checking drive /dev/sda9: 11% (stage 1/5, 1/79)
/dev/sda9: Inodes that were not part of a corrupted orphan linked list found. fsck died with exit status 4
when i booted gutsy from another partition i was able to repair the problem with fsck
sam@oberon:~$ sudo fsck -y /dev/sda9
fsck 1.40.2 (12-Jul-2007)
e2fsck 1.40.2 (12-Jul-2007)
/dev/sda9 contains a file system with errors, check forced.
Pass 1: Checking inodes, blocks, and sizes
Inodes that were part of a corrupted orphan linked list found. Fix? yes
Inode 294516 was part of the orphaned inode list. FIXED.
Inode 1153183 was part of the orphaned inode list. FIXED.
Running additional passes to resolve blocks claimed by more than one inode...
Pass 1B: Rescanning for multiply-claimed blocks
Multiply-claimed block(s) in inode 97482: 232785 232786 232787 232788 232789
Multiply-claimed block(s) in inode 97821: 223622 223623 232785 232786 232787 232788 232789 232790 232790
Multiply-claimed block(s) in inode 98127: 538587 538588 538589 538590 538593 538593
Multiply-claimed block(s) in inode 98135: 538576 538577 538578 538579 538580 538581 538582 538583 538583 538587 538588 538589
Multiply-claimed block(s) in inode 131581: 538576
Multiply-claimed block(s) in inode 131584: 538577 538578 538579 538580 538581 538582 538590
Multiply-claimed block(s) in inode 1169003: 223622 223623
Pass 1C: Scanning directories for inodes with multiply-claimed blocks
Pass 1D: Reconciling multiply-claimed blocks
(There are 7 inodes containing multiply-claimed blocks.)
File /var/lib/
has 5 multiply-claimed block(s), shared with 1 file(s):
Clone multiply-claimed blocks? yes
File /var/log/syslog.0 (inode #97821, mod time Sat Mar 29 12:38:09 2008)
has 9 multiply-claimed block(s), shared with 2 file(s):
Clone multiply-claimed blocks? yes
File /var/log/messages (inode #98127, mod time Sun Mar 30 10:54:00 2008)
has 6 multiply-claimed block(s), shared with 2 file(s):
Clone multiply-claimed blocks? yes
File /var/log/kern.log (inode #98135, mod time Sun Mar 30 10:54:13 2008)
has 12 multiply-claimed block(s), shared with 3 file(s):
Clone multiply-claimed blocks? yes
File /var/cache/
has 1 multiply-claimed block(s), shared with 1 file(s):
Multiply-claimed blocks already reassigned or cloned.
File /var/cache/
has 7 multiply-claimed block(s), shared with 2 file(s):
Multiply-claimed blocks already reassigned or cloned.
File /home/sam/
has 2 multiply-claimed block(s), shared with 1 file(s):
Multiply-claimed blocks already reassigned or cloned.
Pass 2: Checking directory structure
Entry 'dpkg.status.1.gz' in /var/backups (102619) has deleted/unused inode 97829. Clear? yes
Entry '%gconf.xml' in /home/sam/
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Inode 97482 ref count is 1, should be 2. Fix? yes
Unattached inode 97686
Connect to /lost+found? yes
Inode 97686 ref count is 2, should be 1. Fix? yes
Unattached inode 1204250
Connect to /lost+found? yes
Inode 1204250 ref count is 2, should be 1. Fix? yes
Pass 5: Checking group summary information
Block bitmap differences: -(204832--204834) -(396515--396519) -516406 -(516585--516590) -(516599--516602) -520920 +(538553--538554) -713526 -(1086379--1086426) -(2356655--2356658)
Fix? yes
Free blocks count wrong for group #1 (21, counted=0).
Fix? yes
Free blocks count wrong for group #6 (1, counted=4).
Fix? yes
Free blocks count wrong for group #12 (383, counted=388).
Fix? yes
Free blocks count wrong for group #15 (11864, counted=11876).
Fix? yes
Free blocks count wrong for group #16 (6344, counted=6363).
Fix? yes
Free blocks count wrong for group #21 (6, counted=7).
Fix? yes
Free blocks count wrong for group #33 (0, counted=48).
Fix? yes
Free blocks count wrong for group #71 (98, counted=102).
Fix? yes
Free blocks count wrong (172633, counted=172704).
Fix? yes
Inode bitmap differences: -99319 -292135 -294516 -1153183 -1201104 +1204250
Fix? yes
Free inodes count wrong for group #6 (9591, counted=9592).
Fix? yes
Free inodes count wrong for group #18 (13732, counted=13734).
Fix? yes
Free inodes count wrong for group #71 (8505, counted=8506).
Fix? yes
Free inodes count wrong (1058740, counted=1058744).
Fix? yes
/dev/sda9: ***** FILE SYSTEM WAS MODIFIED *****
/dev/sda9: 222952/1281696 files (2.8% non-contiguous), 2387647/2560351 blocks
sam@oberon:~$ sudo fsck -y /dev/sda9
fsck 1.40.2 (12-Jul-2007)
e2fsck 1.40.2 (12-Jul-2007)
/dev/sda9: clean, 222952/1281696 files, 2387647/2560351 blocks
i was then able to mount sda9.
it seems to me that hardy's fsck should have been able to fix this, and not get stuck in a reboot loop.

{kind=link}
{kind=link}
The "getting stuck in a reboot loop" part is possibly a duplicate of bug 204097.