Speed up find* methods by 2x in common cases by checking the tag name first
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| Beautiful Soup |
Fix Released
|
Undecided
|
Unassigned | ||
Bug Description
The attached patch makes beautifulsoup twice as fast.
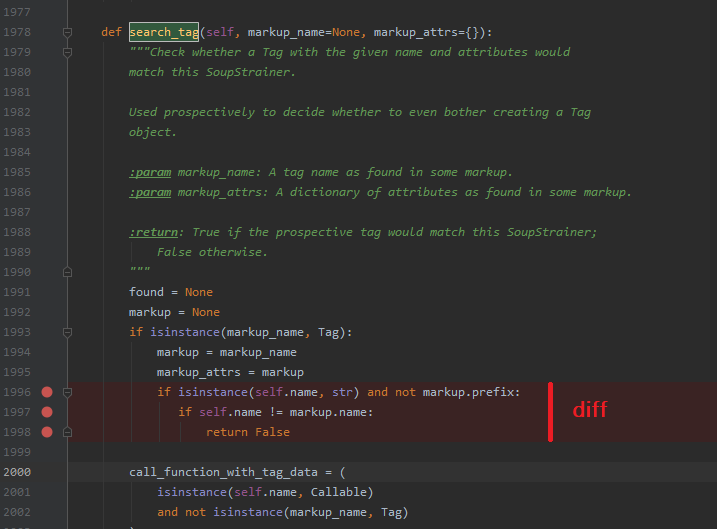
See function search_tag() in element.py. Edit the 3 lines.
Tested on beautifulsoup 4.9.1, lxml 4.5.2, python 3.7, windows 10.
How does this work?
find(something) iterates on the children elements, calling search_tag() to verify whether an element is a match for the filter, calling _matches() to perform the node comparison. It's basic AST tree parsing, nothing fancy.
This is horribly slow in python because it's running millions of lines of code, effectively a loop in a loop:
- Iterating through all the HTML/XML elements. Consider a bazillion elements in a large page.
- Comparing each element to the filter. Node comparison is a rather heavy recursive operation (see _matches).
If you think about how HTML is used and processed, a find("body") is going through a bazillion elements that are not a "body" hoping to find the one "body". Unfortunately the name comparison "body"=
The patch adds an early comparison on the tag name. An element can't be a match if the name doesn't match, check for this early and abort never entering the heavy recursive comparison. (note: doesn't apply if there is a prefix on the node because prefixes affect names)
Result:
This improves search by tags, including find("tag") find_all("tag").
I suppose that's 90% of what people do with beautifulsoup so that's a massive speed improvement for the entire planet.
Let me know if you can see the patch. Note sure the attachment is working.
I have a code snippet for repro, text output showing software can run in 53% of the original time over various scenarios and screenshots of python profilers showing line by line information with bottlenecks. But I can't figure out how to attach any of that, doesn't seem to be support for attachments.
Really wish the project was on GitHub instead of this strange thing. ;)
Next:
Can probably do a similar thing with attributes.
If a search involves attributes and an element has no attributes, same thing, it's not going to match, could exit early.

{kind=link}
{kind=link}
| Changed in beautifulsoup: | |
| status: | New → Fix Committed |
| summary: |
- patch: make beautifulsoup twice as fast + Speed up find* methods by 2x in common cases by checking the tag name + first |
benchmark results, not patched.